在本地构建隐私优先的离线 AI 助手 (Qwen, DeepSeek, Llama)
你发送给 ChatGPT 或 GitHub Copilot 的每一行代码都会离开你的机器。对于专有代码库、医疗应用程序或金融系统来说,这是一个无法接受的选项。但在本地运行 AI 以前需要机器学习博士学位。
现在不需要了。 使用 Ollama 和 FlyEnv,你可以完全离线运行最先进的语言模型——只需几分钟,而不是几天。
为什么离线 AI 很重要
云 AI 的隐私问题
当你使用基于云的 AI 编码助手时:
- 你的专有代码会传输到外部服务器
- 训练数据可能会保留敏感代码片段
- 合规违规(HIPAA、GDPR、SOC2)
- 网络延迟降低响应速度
- API 成本不断累积
离线 AI 的优势
| 方面 | 云 AI | 本地 AI (Ollama) |
|---|---|---|
| 数据隐私 | 发送给第三方 | 永远不会离开你的机器 |
| 需要互联网 | 是 | 否 |
| 响应速度 | 500毫秒-2秒 | 50-500毫秒(本地) |
| 月度成本 | $10-20/用户 | 免费 |
| 自定义 | 有限 | 完全控制模型 |
| 合规性 | 复杂 | 简单直接 |
你将构建什么
一个完全本地的 AI 助手,可以:
- 回答编程问题
- 解释复杂函数
- 生成代码片段
- 审查 Pull Request
- 全部无需互联网连接
前提条件
硬件要求
| 模型大小 | 所需内存 | 最佳用途 |
|---|---|---|
| 3B 参数 | 4GB | 基础编码帮助 |
| 7B 参数 | 8GB | 通用开发 |
| 13B 参数 | 16GB | 复杂推理 |
| 70B 参数 | 64GB+ | 企业级应用 |
推荐:16GB+ 内存用于多功能编码辅助
软件
- 已安装 FlyEnv(macOS、Windows 或 Linux)
- ~10GB 可用磁盘空间用于存储模型
分步设置指南
第一步:安装 Ollama
FlyEnv 让这个过程变得一键简单:
- 打开 FlyEnv
- 导航到 Ollama 模块
- 点击 安装
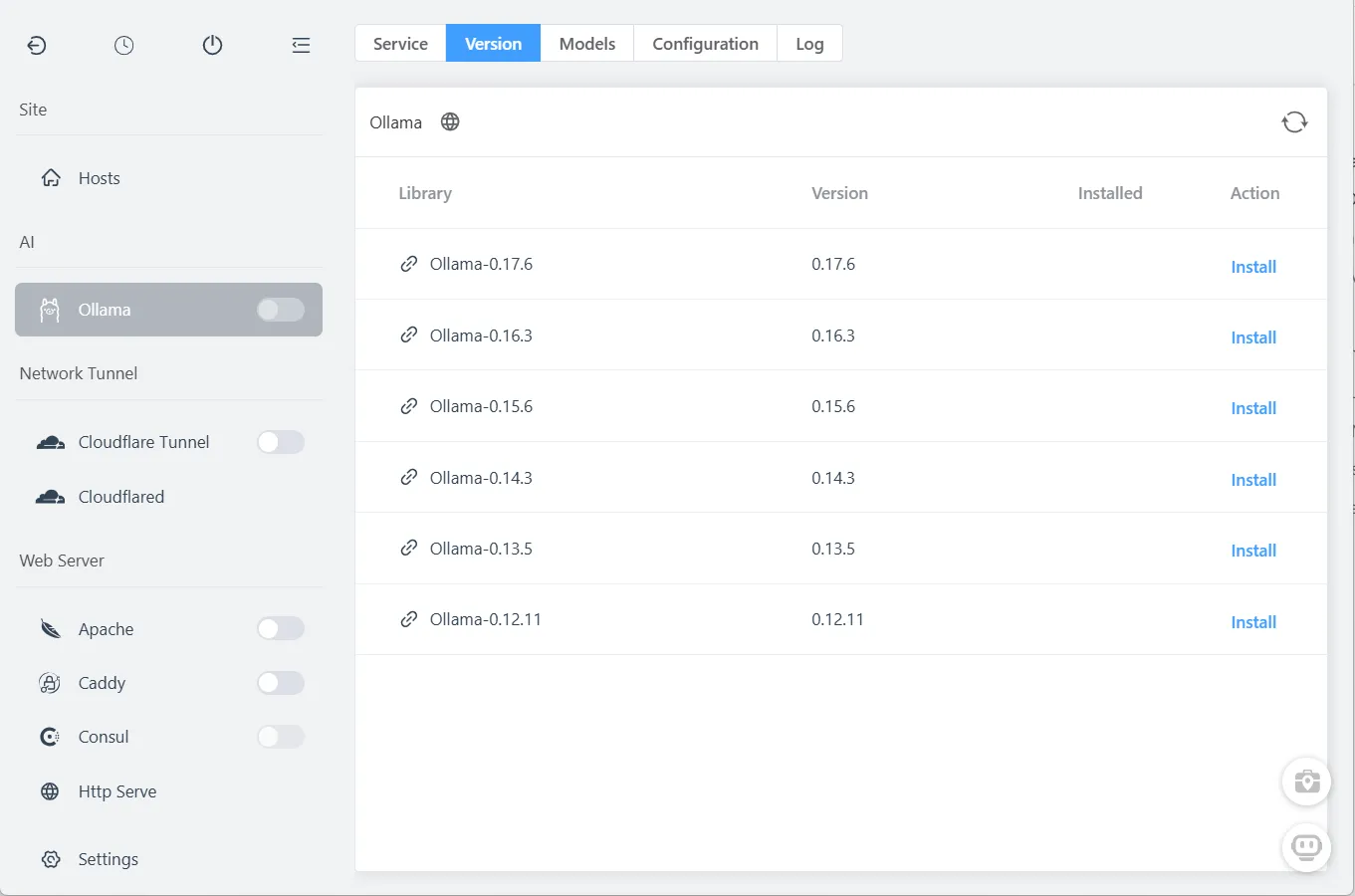
Ollama 作为原生服务安装——无需 Docker 容器,无需配置 Python 环境。
第二步:启动 Ollama 服务
在 Ollama 模块中:
- 点击 启动 按钮
- 验证服务状态显示为"运行中"

Ollama API 现在可以在 http://127.0.0.1:11434 访问
第三步:下载 AI 模型
FlyEnv 提供对流行模型的便捷访问:
| 模型 | 大小 | 优势 |
|---|---|---|
| DeepSeek-R1 | 7B-70B | 代码生成、推理 |
| Llama 3.3 | 8B-70B | 通用目的、均衡 |
| Qwen 2.5 | 7B-72B | 多语言、编码 |
| Phi-4 | 14B | 微软研究模型 |
| Mixtral | 8x7B | 专家混合模型 |
安装模型:
- 在 Ollama 模块中,切换到 模型 标签页
- 选择一个模型(16GB 内存建议从 7B 开始)
- 点击 拉取
下载进度实时显示。首次下载可能需要 10-30 分钟,取决于模型大小和网络连接。

专业提示:从 Qwen 2.5 7B 或 DeepSeek-R1 7B 开始,可以在不占用大量资源的情况下获得出色的编码辅助。
第四步:启用 AI 助手界面
- 打开 FlyEnv 设置
- 找到 AI 助手 部分
- 打开 启用 AI 助手 开关

第五步:打开聊天界面
点击右下角的 AI 助手 图标:

聊天界面打开,准备进行交互。
第六步:配置 Ollama 连接
在 AI 助手面板中:
- 点击 设置(齿轮图标)
- 设置 API URL:
http://127.0.0.1:11434 - 从下拉菜单中选择你已安装的模型
- 点击 保存
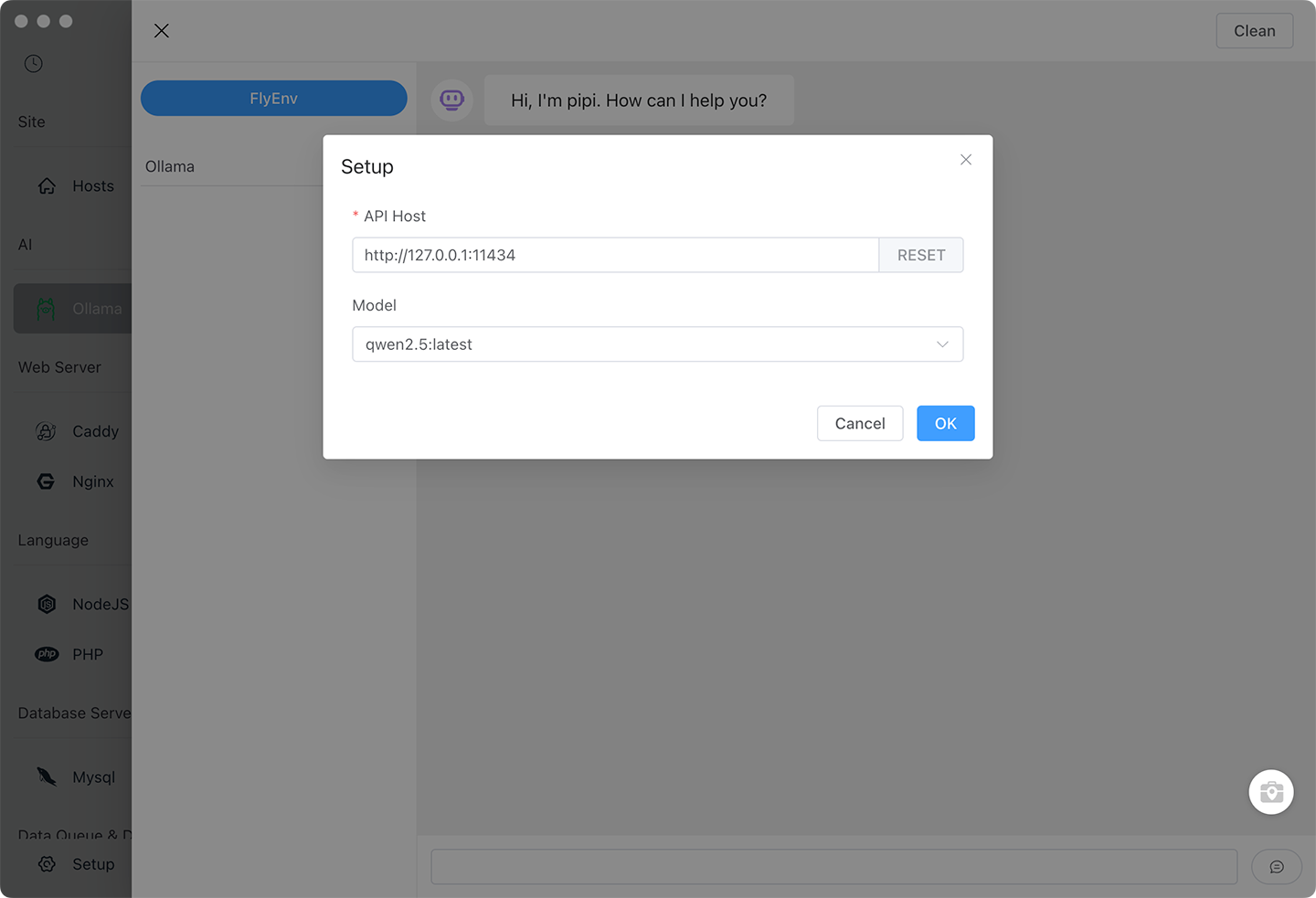
团队设置:对于共享 AI 资源,输入同事的 Ollama 服务器 IP。一台强大的工作站可以为整个团队服务。
第七步:开始你的第一次聊天
点击 新建聊天 并提出任何问题:
你:解释这个 PHP 函数:array_reduce()
AI: array_reduce() 使用回调函数将数组迭代地减少为单个值...
你:生成一个模态对话框的 React 组件
AI: [生成完整、带样式的组件代码]

使用 AI 进行开发工作流
代码解释
粘贴复杂代码并要求解释:
"解释这个 Laravel Eloquent 查询是做什么的..."
"这个算法的时间复杂度是多少?"
"这个递归函数是如何工作的?"代码生成
快速生成样板代码:
"创建一个用于用户 CRUD 操作的 NestJS 控制器"
"编写一个 Python 脚本解析 CSV 并插入到 MySQL"
"为 PHP、MySQL、Redis 生成一个 Docker Compose 文件"代码审查
粘贴代码获取即时反馈:
"审查这个函数的安全问题"
"我如何优化这个数据库查询?"
"这是在 Go 中实现此功能的惯用方式吗?"学习辅助
"像给 5 岁小孩一样解释 React hooks"
"var、let 和 const 有什么区别?"
"教我关于 PHP 中的依赖注入"高级功能
基于角色的提示
AI 助手支持不同的角色:
点击 角色 选择器
从预设中选择:
- 代码审查者:对代码质量进行批判性分析
- 教师:耐心地解释概念
- 架构师:高级系统设计建议
- 调试器:专注于发现和修复错误
或创建自定义角色:
角色:Laravel 专家 提示词:你是一位拥有 10 年经验的资深 Laravel 开发者。 提供最佳实践解决方案并解释"Laravel 风格"。

响应操作
每个 AI 响应都提供:
- 复制:复制代码块或整个响应
- 朗读:文本转语音,提高可访问性
- 重新生成:尝试不同的响应
- 继续:扩展部分答案

多模型对比
并排运行不同的模型:
- 打开多个聊天标签页
- 为每个标签页配置不同的模型
- 提出相同的问题
- 比较响应
这有助于确定哪个模型最适合你的特定用例。
性能优化
模型大小与质量
| 使用场景 | 推荐模型 | 响应时间 |
|---|---|---|
| 快速查询 | Qwen 2.5 3B | <100毫秒 |
| 日常编码 | DeepSeek-R1 7B | 200-500毫秒 |
| 复杂架构 | Llama 3.3 13B | 500毫秒-1秒 |
| 代码审查 | Qwen 2.5 32B | 1-3秒 |
GPU 加速
在 macOS 上,Ollama 自动使用 Apple Silicon 神经引擎。
在带 NVIDIA GPU 的 Linux/Windows 上:
# 如果可用,Ollama 会自动使用 CUDA
# 验证 GPU 使用情况:
ogpu-smi # 或 nvidia-smi模型管理
通过删除未使用的模型释放磁盘空间:
# 在终端中
ollama rm llama2:13b # 删除特定模型
ollama list # 查看已安装的模型常见问题 (FAQ)
Q: 这真的完全离线吗?
A: 是的。一旦模型下载完成,就不需要互联网连接。你的数据永远不会离开你的机器。
Q: 这与 GitHub Copilot 相比如何?
A: Copilot 提供 IDE 集成和在公共代码上的训练。本地 AI 提供隐私和零成本。许多开发者两者都用:Copilot 用于公共项目,本地 AI 用于专有工作。
Q: 我可以使用自己的微调模型吗?
A: 是的。Ollama 支持 GGUF 格式模型。将它们放在 Ollama 的模型目录中。
Q: 为什么响应质量比 ChatGPT 低?
A: 本地 7B 模型比 GPT-4 小。对于编码任务,它们 surprisingly 能干。对于复杂推理,更大的模型(13B-70B)能显著缩小差距。
Q: AI 可以访问我的项目文件吗?
A: 不能自动访问。你需要将代码粘贴到聊天中。未来的 FlyEnv 版本可能会添加 IDE 集成。
Q: 这在商业使用上合法吗?
A: 是的。像 Llama、Qwen 和 DeepSeek 这样的模型对商业应用有宽松的许可证。
Q: 这会消耗多少电力?
A: 极少。CPU 推理使用约 10-30W。GPU 推理仅在活跃使用时使用 50-150W。
隐私优先的开发工作流
- 专有代码:专门使用本地 AI
- 开源项目:可以使用任一种
- 客户工作:始终使用本地 AI 处理他们的代码
- 学习:使用本地 AI 进行文档和教程学习
准备好用 AI 隐私编程了吗?
掌控你的开发数据。在几分钟内设置你的离线 AI 助手。
下载 FlyEnv 内置 Ollama 支持
🚀 进阶:从对话到自动化
喜欢你的私有 AI 助手?更进一步,构建自动化 AI 工作流,无需人工干预即可 7×24 小时运行。
你将获得:
- Webhook — 从外部应用(Slack、GitHub、Stripe)触发 AI 处理
- 工作流自动化 — 将多个 AI 操作链接成流水线
- API 端点 — 让你的应用访问本地 AI 模型
- 远程访问 — 从任何地方控制你的 AI 工作流
👉 使用 n8n 和 Ollama 构建自托管 AI 工作流 — 将你的离线 AI 转变为自动化利器
🤖 构建能执行操作的 AI 代理
想要一个不仅能聊天——还能实际为你做事的 AI?OpenClaw 将你的本地 AI 连接到消息应用,并赋予它以下能力:
- 读写文件 — 在你的计算机上操作文件
- 执行命令 — 运行脚本和系统命令
- 发送消息 — 通过 QQ、微信、飞书、WhatsApp、Telegram 等
- 发起 HTTP 请求 — 与 API 交互
👉 OpenClaw + Ollama 配置指南 — 零 API 费用构建自托管 AI 代理
探索更多生产力工具:
- PHP 代码混淆 — 保护你的代码
- Cloudflare Tunnel — 安全分享
- 项目版本管理 — 简化工作流